Cosmetic trials are research studies conducted with participants who test cosmetic treatments with the purpose of assessing their efficacy and safety. While laboratory and in vitro studies are important to assess the efficacy and safety of cosmetics, data from clinical trials hold the most relevance to humans. In effect, testing your product in a clinical trial generates scientific evidence for a product’s efficacy and safety that is most easily generalisable to the real world.
However, not all cosmetic products tested show positive efficacy outcomes in clinical trials and it is important to understand why this occurs. Proper insight into why a product did not perform as expected is fundamental when determining your next steps, which might include re-formulation of the product, a change in how it is applied, or rethinking how your next experiment should be run in order to maximise the chance of finding a positive outcome.
Any positive (or negative) clinical study outcomes are often due to a large combination of factors. Some of these are directly related to the quality of the test products and their performance, which is beyond the scope of this article. Other factors relate to appropriate clinical trial design and associated study protocol, and these may be issues that could be overlooked due to a lack of understanding or familiarity with statistical testing. If the test product is indeed effective and safe for the skin, the data collected during the clinical trial presents two fundamental characteristics:
A) The improvement is substantial over placebo
In clinical studies, the most reliable way to assess the efficacy of a treatment is to compare the tested treatment to a placebo control. The average change from baseline to final visit is calculated for each group and then compared together. When treatments are efficacious, treatment results will be higher than the control or placebo, indicating that participants using the treatment experienced a greater change than those using the placebo. Sometimes, the reason why cosmetic studies fail to show a significant change is that the improvements in both treatment and placebo groups are quite similar. Conversely, if the improvement from baseline is substantially greater in the treatment group compared to the control, this result is more likely to be considered statistically significant.
B) Low variability in the data
When the data collected show high between-subject variability (e.g. the measured effect is positive in some participants and negative in other participants) the effects of the test product are not consistent, and it becomes harder to confidently say that the average across all participants is representative of the true, underlying value. In this case, although on average the results could be somewhat positive, the spread of data can reveal that either the product’s performance or the participants themselves are highly variable, and thus we cannot confidently say that it is significantly different from placebo. Conversely, when the data variability is low, the change after treatment is generally more consistent (e.g. some positive effect in most participants) and therefore displays a better outcome. The lower the variability of data the higher the chances of finding statistical significance in the results.
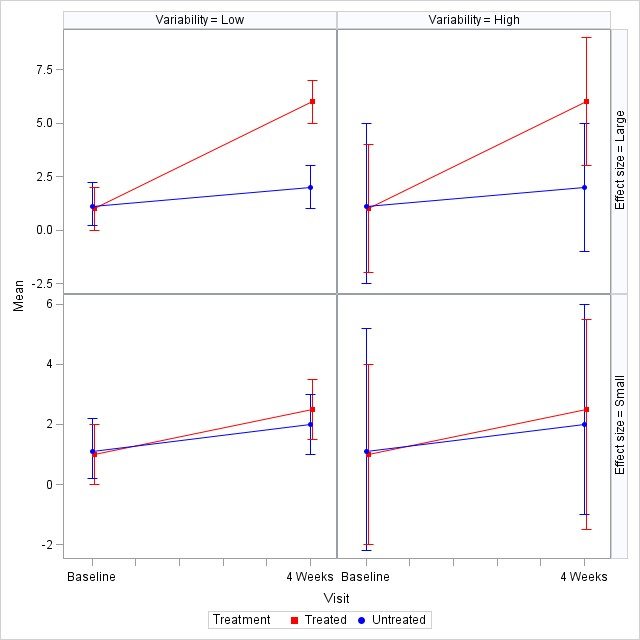
Figure 1 shows sample data for four possible combinations of effect size and variability. While the points discussed above directly involve the test product and the efficacy data collected throughout the study, below we will touch on some of the elements of the study that may influence the values (point A) and the variability (point B) of the obtained data. All points below are equally important and can ultimately affect the success of a study:
1) Study inclusion/exclusion criteria
Improvement in skin parameters are commonly measured in comparison with baseline (before commencement of the cosmetic treatment) and with a control or placebo. Therefore, to measure a change it is essential that baseline conditions are such that an improvement can occur. Unless the experimental design requires so, there is no point in testing the efficacy of a moisturiser in participants whose skin is already hydrated, for the same reason that you would not enrol young women in an anti-ageing study – participants are unlikely to improve no matter how good your product is!
A study’s inclusion and exclusion criteria must take into consideration the target population (i.e. consumers that are likely to use the test product) and exclude those participants that would not benefit from using the test product, as they do not present with the characteristics the test product is intended to improve. Once the target population has been identified, baseline conditions should confirm that improvement with certain skin characteristics is needed, which then allows the product’s efficacy to be properly assessed.
2) Correct sample size
The size of sample population (i.e. the number of participants in the study) required will depend on the expected size of the effect to be detected, the variability of the data and the power of the study. In general, you will require more participants when aiming to detect a small effect, if you suspect your measurements to be variable, or if you want a greater certainty that the effect you detected is true. For example, the smaller an effect you wish to detect, the larger your study needs to be (all other factors being constant). Conversely, the more effective the product the less study participants you need to find a significant effect.
The power of a study is the probability that it will detect a difference of the magnitude specified if it truly exists. The size of a study should always be large enough to provide a reliable answer to the questions addressed (i.e. have sufficient power). The importance of getting sample size right cannot be overstated: studies with few participants may not allow the detection of differences between groups (It is typical to size studies based on 80% or 90% power). On the other hand, an excess of participants will not only be unnecessary, but costly too. This is why sample size calculation is determined by a statistician based on the primary objective of the study, or by a justification based on statistical and/or methodological expertise (background data, former study, and so on).
3) Duration of the study
Duration of the treatment is also key in a study design and needs to be carefully considered to ensure the best outcome. In some cases, a certain study duration may not seem sufficient to show maximum effect if the effect of the product is a gradual one. In comparison, a longer study could have detected at least an overall trend, which is another method of measuring efficacy (separate from change from baseline to final value). However, a longer study duration does not guarantee better results, it merely provides a greater window in which to detect an effect of the tested product, if that effect indeed exists.
If a trial is successful, the test product group will have a statistically significant greater change from baseline when compared to the control, and this change will have low variability within each test group. When the results of a trial are ‘not statistically significant’ it means that any observed differences between treatment and control are most likely due to chance. However, it doesn’t mean that there truly is no difference, or that the treatment is necessarily ineffective. As discussed above, significant differences in treatment effects in comparison trials might be missed due to other reasons, including incorrect study design in crucial areas such as inclusion/exclusion criteria, sample size and study duration, and should be taken into consideration when assessing your next steps.
References:
Ediléia Bagatin and Helio A. Miot, “How to design and write a clinical research protocol in Cosmetic Dermatology”, An Bras Dermatol. 2013 Jan-Feb; 88(1): 69–75.
David J. Slutsky, “Statistical Errors in Clinical Studies”, J Wrist Surg. 2013 Nov; 2(4): 285–287.
Colipa Guidelines, “Efficacy Evaluation of Cosmetic Products”, May 2008
Zulfiqar Ali and S Bala Bhaskar, “Basic statistical tools in research and data analysis”, Indian J Anaesth. 2016 Sep; 60(9): 662–669.
Michael Bigby and Hywel C. Williams, “Principles of Evidence-based Dermatology” Rook’s Textbook of Dermatology Part 1 Ch 17.

